Deep Dive · P1
Log-Replay Evaluator — How it works
Architecture
src/evaluator/ schema.py → Parquet schema + map geometry constants (single source of truth) log_gen.py → synthetic scenario generator (PyArrow + NumPy) metrics.py → 5 pure metric functions (Pandas / SciPy) cli.py → Click CLI wiring everything together ┌─────────────┐ ┌──────────────┐ Parquet ┌─────────────────┐ MetricResult[] ┌─────────────┐ │ schema.py │ ──────▶ │ log_gen.py │ ─────────▶ │ metrics.py │ ───────────────▶ │ cli.py │ │ (schema + │ │ (3 scenarios)│ │ (5 pure fns) │ │ JSON + PNG │ │ geometry) │ ──────▶ └──────────────┘ └─────────────────┘ └─────────────┘ └─────────────┘
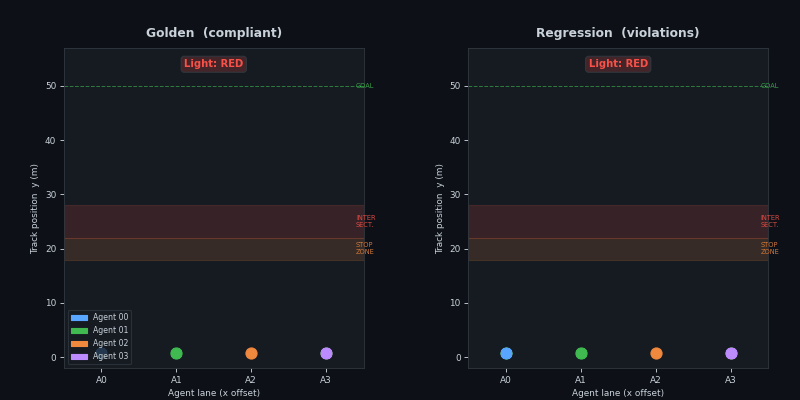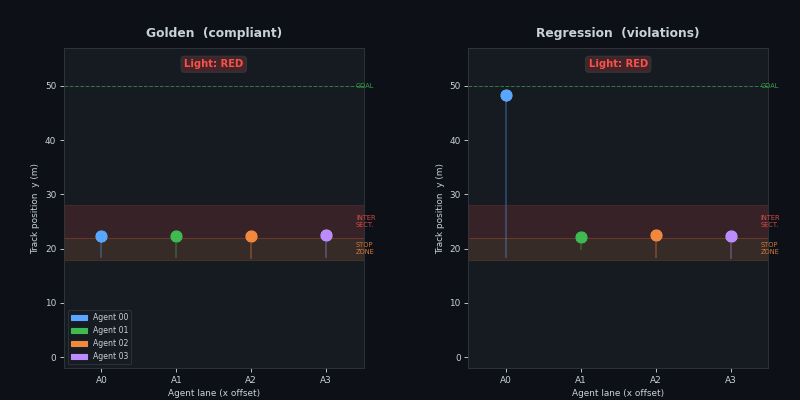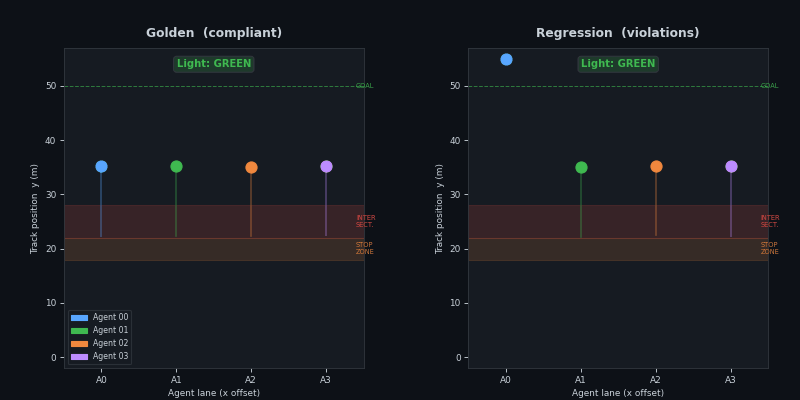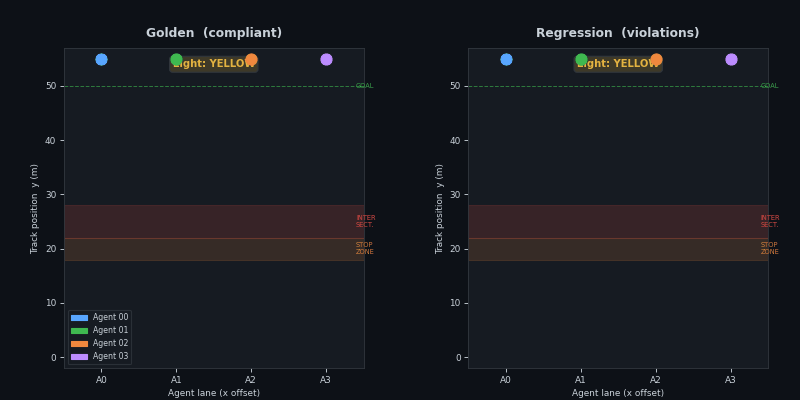
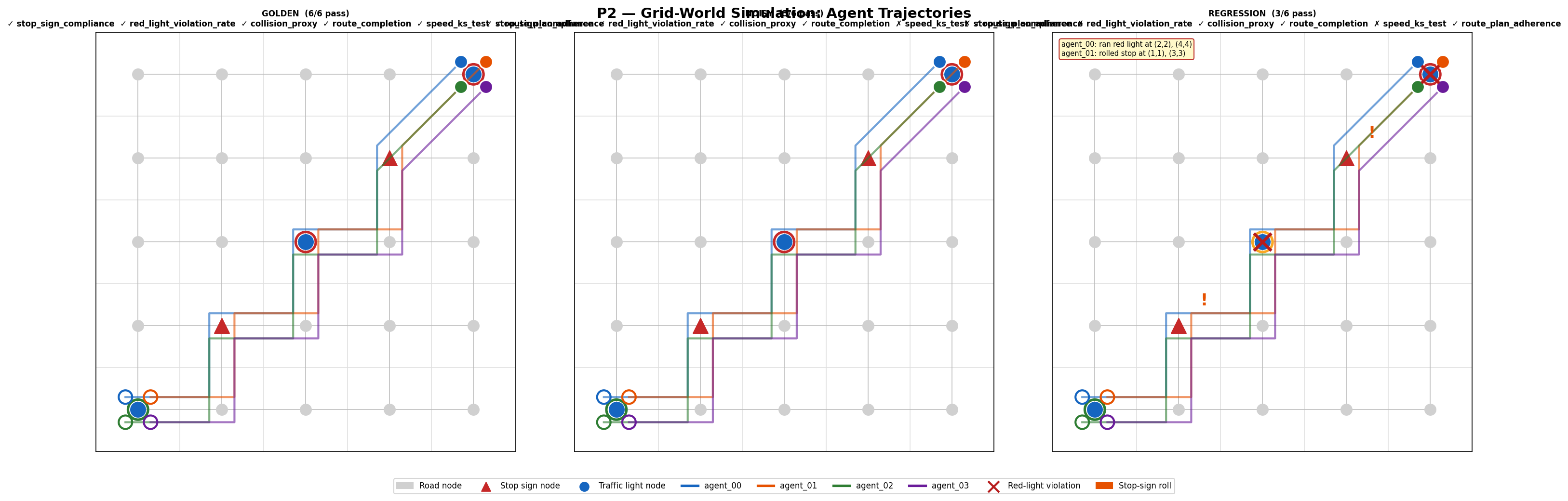
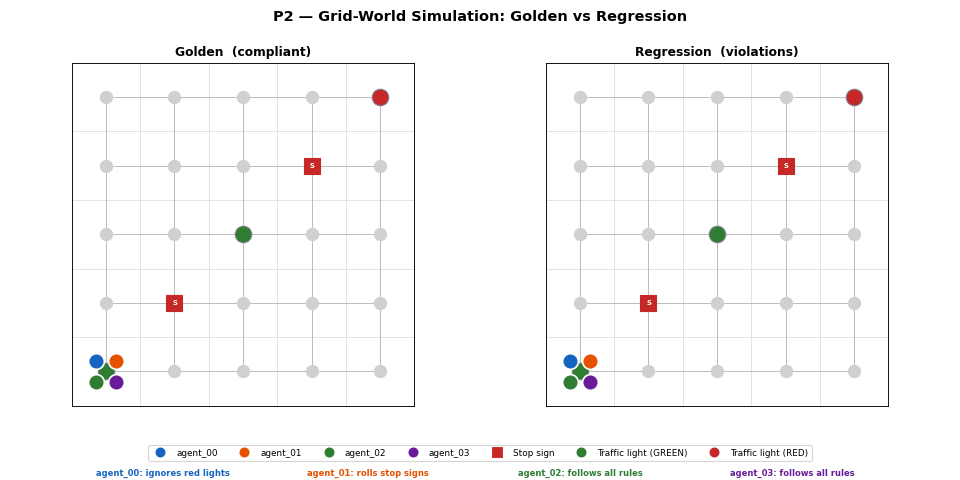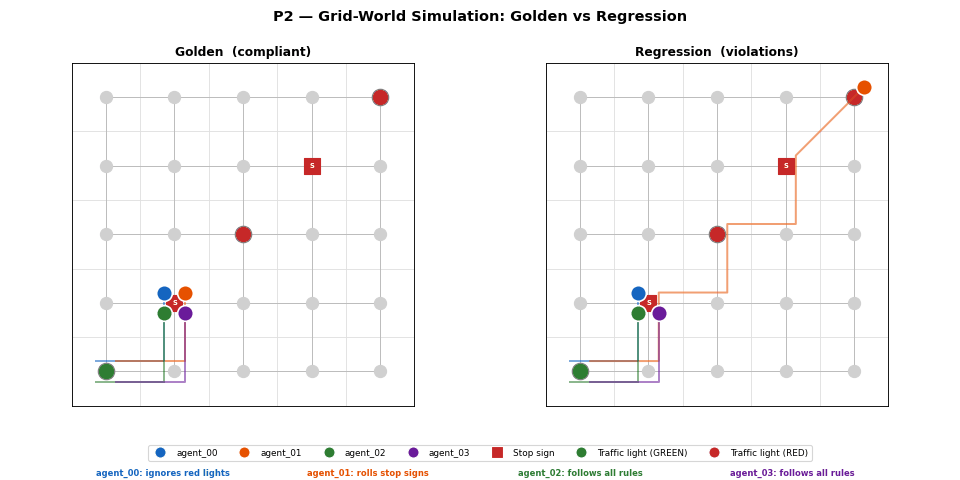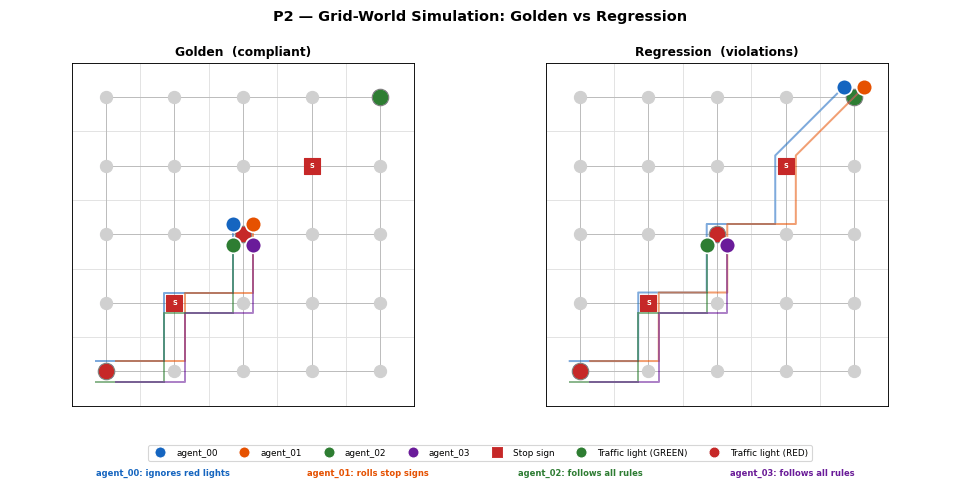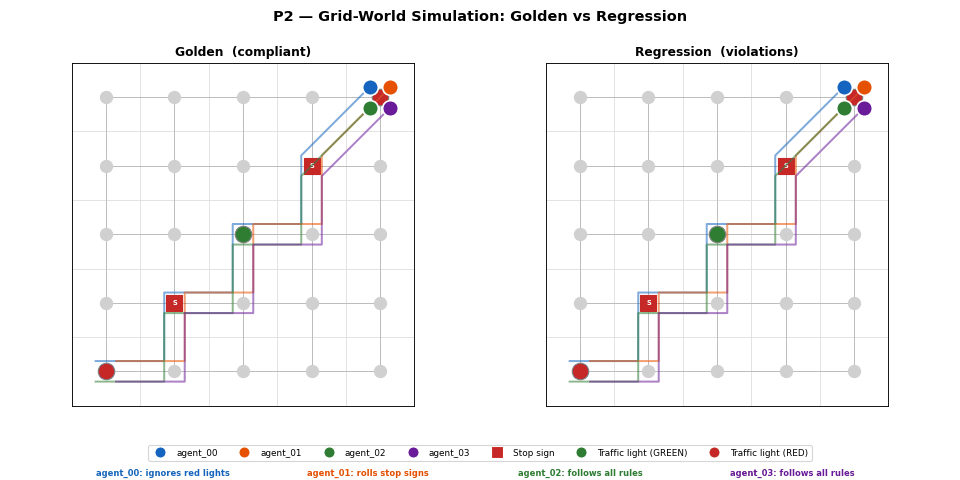
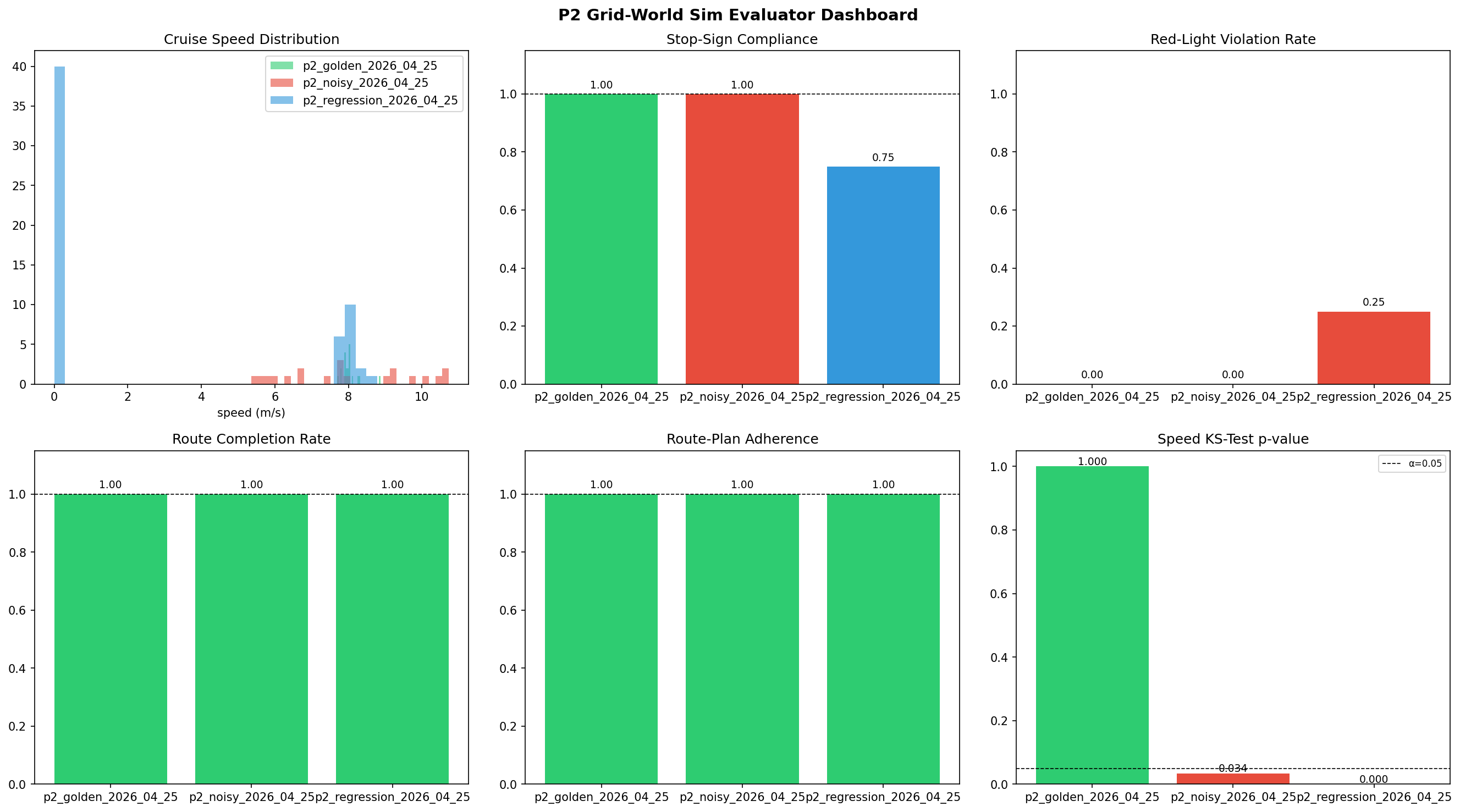
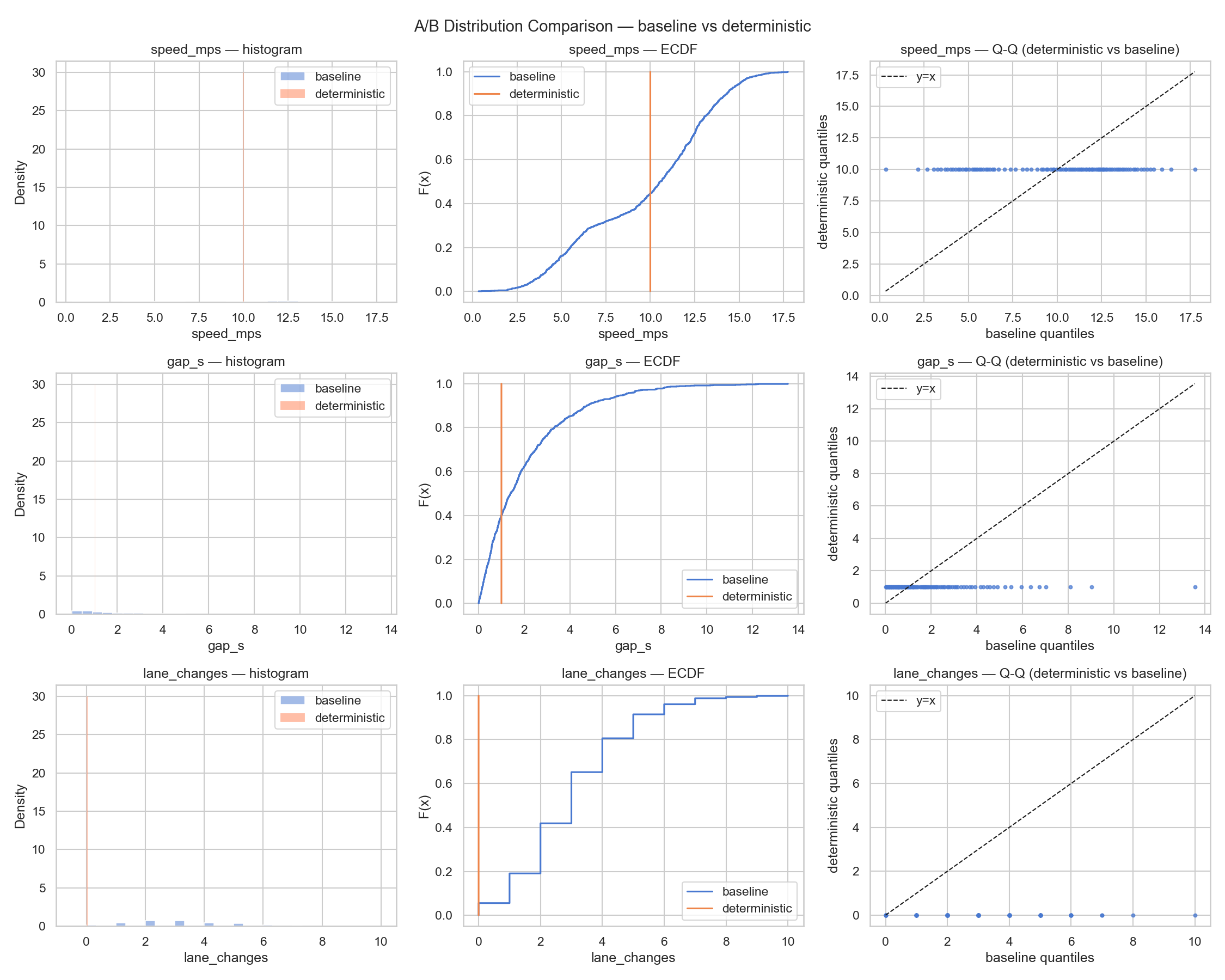
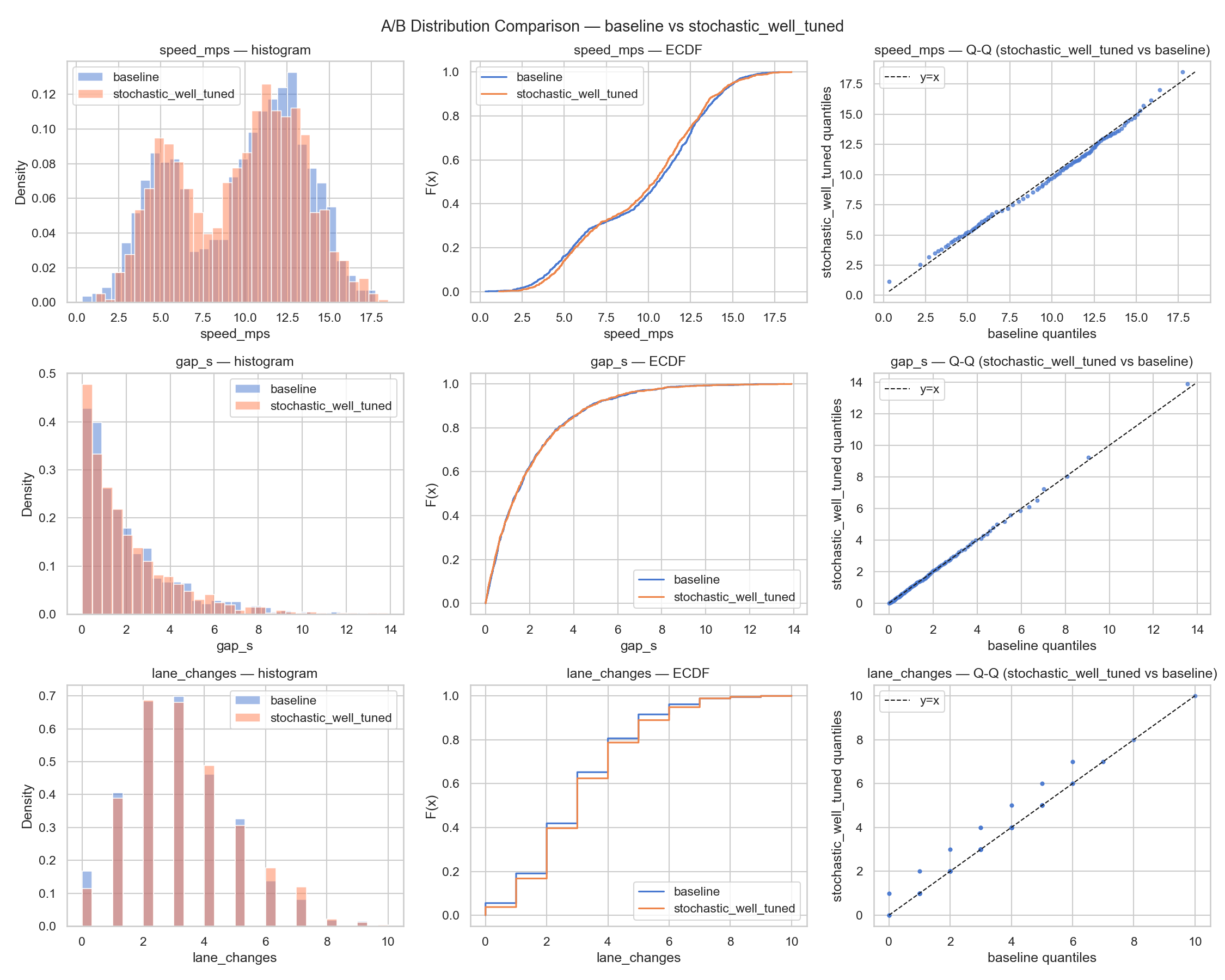
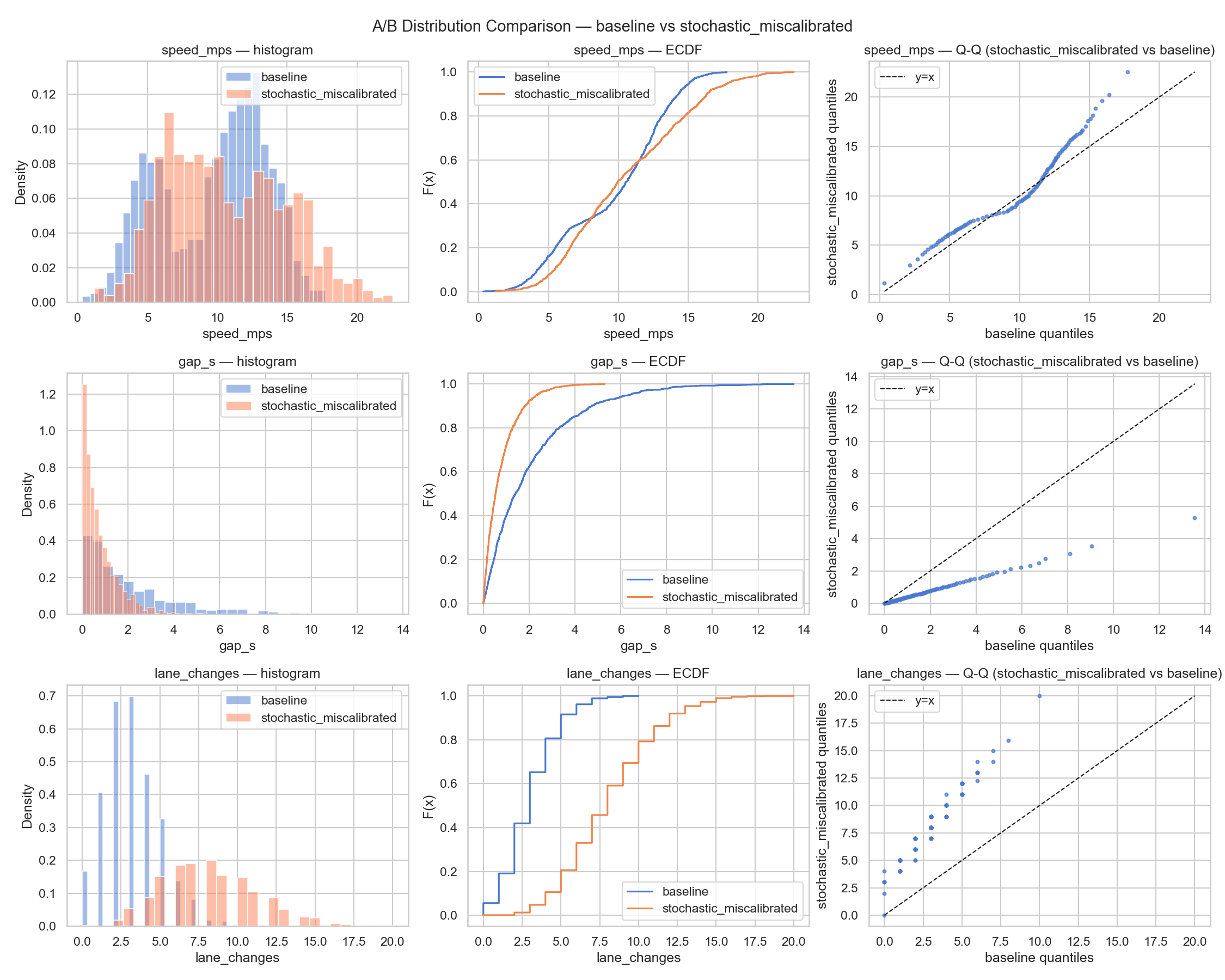
Metrics — 3-scenario comparison
Loading metrics…
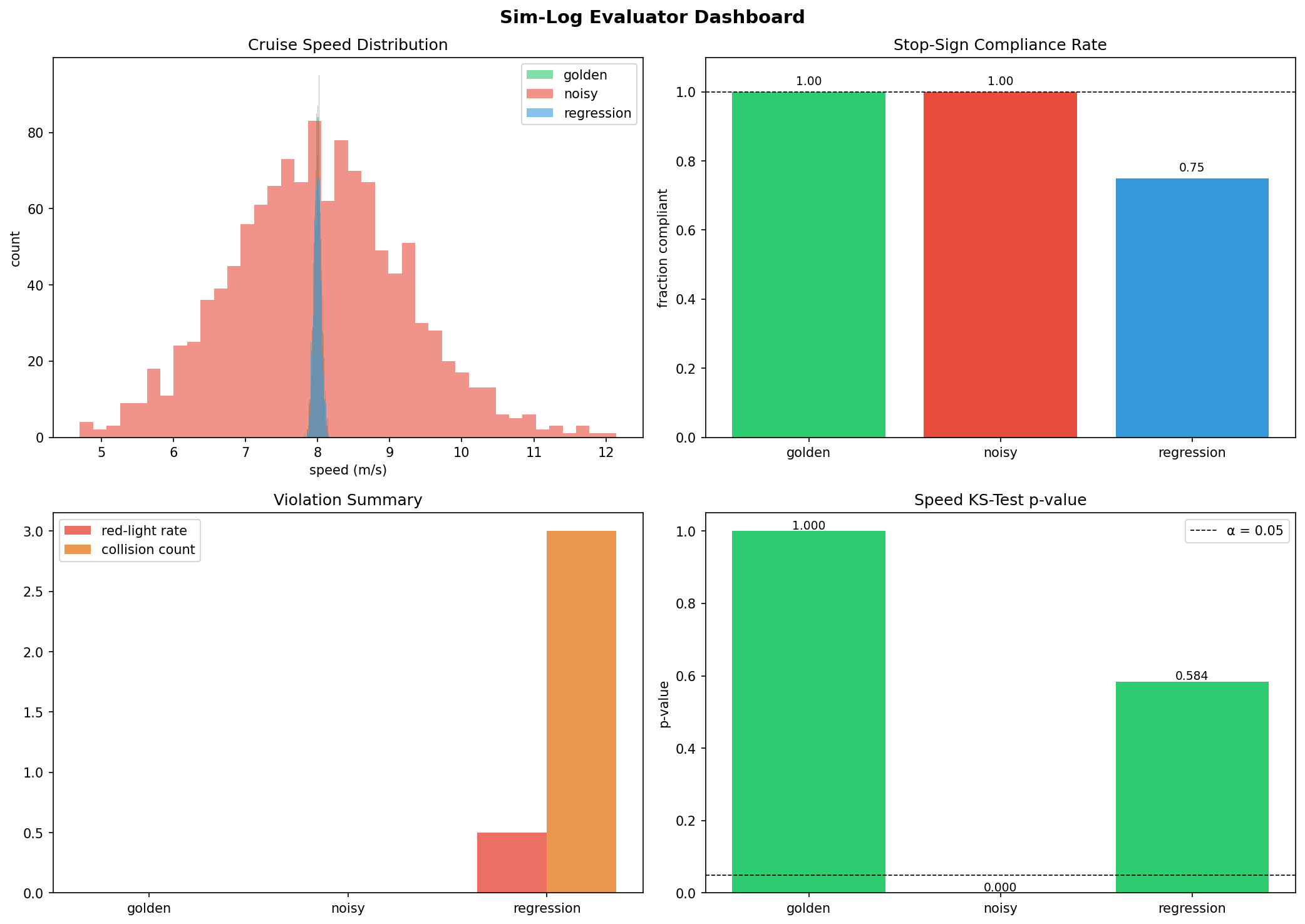
P1 dashboard: speed histogram, stop compliance bar, violation summary, and KS p-value across all 3 scenarios